今回はNode.jsのライブラリであるPlaywrightを使って簡単なWebスクレピングを実装していきます。基本的な導入部分についてを備忘録としてまとめています。
目次
ゴール
- Googleのトップページへアクセスし、検索画面をスクリーンショットする動作を再現すること
- TypescriptによるPlaywrightの基本的な使い方を把握すること
Playwrightとは
Playwrightとは、Microsoftが開発したブラウザを操作するためのNode.jsのライブラリです。
Node.jsの場合、以前まではPuppeteerがよく使用されていましたが、Playwrightはその上位互換となります。Puppeteerの開発をしていたメンバーが中心となってPlaywrightを開発しているとのことです。
そのため、Puppeteerを触ったことがあれば、非常に良く似た作りとなっているため扱いやすいかと思います。
参考リンク
- 公式Doc:https://playwright.dev/docs/api/class-playwright
- Github:https://github.com/microsoft/playwright
開発環境
- 実行環境
- Node.js:
v16.18.1 - npm:
v8.19.2
- Node.js:
- ライブラリ
- playwright-core:
v1.28.1 - typescript:
v4.9.3
- playwright-core:
開発環境構築
各種インストール
$ npm init --yes
$ npm install playwright-core
$ npm install --save-dev typescript @types/node@16 ts-node
$ npx tsc --init※ playwright-core
ここでは、PCに既にインストールされているchromeブラウザを使用するため、playwright-coreをインストールしています。
特にこだわりがない場合は、playwrightでも大丈夫ですが、各種ブラウザがDLされるので少し時間がかかります。
設定ファイルの追加
tsconfig
{
"compilerOptions": {
"target": "es2016",
"module": "commonjs",
"baseUrl": "./src",
"outDir": "./dist",
"sourceMap": true,
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true
}
}package.json
{
"name": "ts_playwright",
"version": "1.0.0",
"main": "sample.scraper.js",
"scripts": {
"build": "npx tsc",
"build:watch": "npx tsc --watch",
"start:scraper": "node ./dist/sample.scraper.js"
},
"dependencies": {
"playwright-core": "^1.28.1"
},
"devDependencies": {
"@types/node": "^16.18.3",
"ts-node": "^10.9.1",
"typescript": "^4.9.3"
}
}コード実装
最終形
ディレクトリ構成
.
├── dist
│ └── sample.scraper.js
├── src
│ └── sample.scraper.ts
├── tmp
│ └── example.png
├── package-lock.json
├── package.json
└── tsconfig.json実行ファイル
import { chromium } from 'playwright-core';
(async () => {
const browser = await chromium.launch({
channel: 'chrome', //ここで指定することで既存のchromeを利用可能
headless: true, //falseの場合はブラウザ上での動きを確認しながら実行可能
}); //①ブラウザ起動
const page = await browser.newPage(); //②ページ生成
await page.goto('https://www.google.co.jp/'); //③サイトへアクセス
await page.screenshot({ path: `tmp/sample.png` }); //④スクリーンショット
await browser.close(); //⑤ブラウザ終了
})();基本的な処理フロー
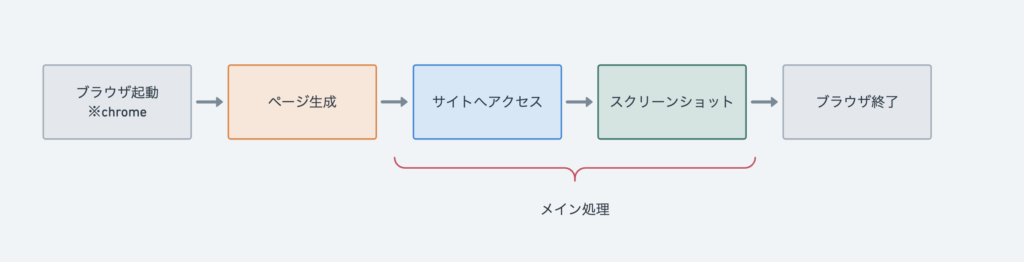
メイン処理の部分を変えていけば汎用的にスクレイピングが可能です
スクレイピング実行
$ npm run start:scraper実行後、tmp配下にGoogleの検索ページがスクショされていれば成功です。
さいごに
Playwrightを使って基本的なWebスクレイピングを実装してみました。
メイン処理の部分を対象サイト、収集したい情報に合わせて実装していけば様々なことが出来るかと思います。
今後もPlaywrightに関する記事を書いていきますので、ぜひ参考にして頂ければと思います。